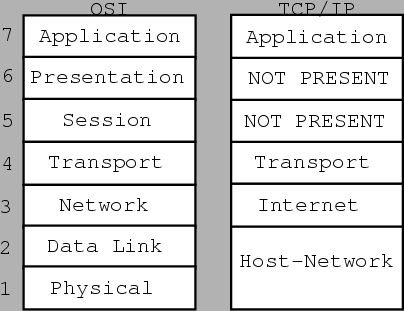
The Open Systems Incorporated (OSI) introduced a model for networking consisting
of 7 layers. They called this model the OSI model, and it was to become a standard
for networking. However, it was not very widely implemented and is used mainly
as a reference model. The TCP/IP model is a simpler model which is widely used
on the Internet. TCP/IP stands for Transmission Control Protocol/Internet Protocol.
It was designed to connect multiple networks together in a seamless way, survive
loss of subnet hardware with conversation not broken off, and to be flexible.
The very name itself was taken from its two primary protocols. The TCP/IP and
OSI protocol stacks are shown in figure 4.1.
Layers 1 and 2 of the OSI model correspond to one layer called the Host-Network layer in the TCP/IP model. This layer is responsible for any conversion and the communication needed to ``put the message on the wire''. Layer 3 of the TCP/IP model is called the Internet layer and corresponds to the Network layer of the OSI. This layer is responsible for routing and addressing information that needs to be put into the packet4.1. These packets, with their addressing information, are injected into the network where they must independently find their own way to the destination. Layer 4 of both models above is the Transport layer. It defines the means by which source and destination carry out their conversation. For the TCP/IP model, two end-to-end protocols are defined. The first one, TCP (Transmission Control Protocol) is a reliable connection-oriented protocol for getting information from source to destination without error. The second protocol, UDP (User Datagram Protocol) is a connectionless, unreliable protocol for applications not needing sequencing and other information that TCP provides. We will discuss these protocols in more detail later. Layer 7 of both models, the Application layer, contains all the high level protocols which include TELNET, FTP (File Transfer Protocol) and HTTP (HyperText Transfer Protocol). Information going out moves down the each of the layers from layer 7 to layer 1. The opposite happens for incoming traffic.[29].
TCP/IP is the preferred protocol of the Internet and especially on Ethernet. Ethernet was the medium of choice for networks. With the introduction of fibre optic cabling, it is no longer as popular but is still used extensively because it is cheap and available. Ethernet has a technical name - CSMA/CD - Carrier Sense Multiple Access/Collision Detect. In simple terms, this means that before ``putting anything on the wire'', an ethernet interface listens for any active stations. If there is an active station, it will wait until activity ceases before doing its own transmission. If two stations transmit at the same time, a collision arises. Both stations and all other stations on the wire will recognize this situation and back off. Ethernet interfaces (transceivers) have unique Ethernet addresses which are 48 bits long. These addresses are used to identify both the manufacturer of the card and an actual device on the network. Ethernet is a broadcast medium, with packets broadcast to every machine on the same piece of wire. Every host that receives the packet checks the destination address of the packet against its own. If the addresses match, the packet's contents are read. If the addresses do not match, the packet is discarded.
The IP layer in itself is unreliable and connectionless. Every IP datagram/packet is considered independently of any others. It is for this reason that IP is connectionless. As IP is unreliable, the onus is placed upon higher level protocols to implement reliability and association between datagrams. All IP datagrams have 32-bit source and destination addresses so that each datagram can be delivered and routed independently[23]. Every IP datagram also has a checksum which is calculated only on the header. If the checksum shows an error in the packet, the packet is simply dropped, with the onus placed on the higher level protocols to retransmit it. To allow for the transport of error conditions and diagnostic data, a component part of IP is a protocol called the Internet Control Message Protocol (ICMP).
On networks, there may exist many error conditions and diagnostic codes. For this reason, the ICMP packet can assume a number of forms. ICMP packets are encapsulated in IP packets. The basic structure of the header is fixed while individual field meanings are variable. The Type field of the ICMP header indicates what type of information the ICMP header carries. The header also carries a 16-bit checksum which is the checksum for the entire ICMP message. There is also a Miscellaneous field which contains information for miscellaneous purposes (sequence numbers etc). This is followed by an IP protocol header and a further 8 bytes or test data. The IP header is the triggering IP datagram header. The 8 bytes are either the first 8 bytes of that IP datagram or test data. There are 15 types of ICMP messages that can be transported, examples are illustrated in the table below.
| Type field | Function |
| 0 | Echo reply |
| 3 | Destination unreachable |
| 4 | Source quench |
| 5 | Redirect |
| 8 | Echo Request |
| 11 | Time exceeded for a datagram |
| 12 | Parameter problem on a datagram |
The Internet is made up of medium-to-large networks that are connected to each other. At this point, let us also introduce the idea of a gateway. A gateway is simply a point through which we can get to our destination. An analogy would be a border post: to get to another country, one has to go through the border post. In other words, our route to another country is through a gateway (border post). A gateway does not have to separate two different networks but can be used to divide a single network into areas.
Routing is part of the Internet layer of the TCP/IP stack. IP also being at this layer means that IP datagrams are to be routed. Each host on the Internet has to have a unique 32-bit address. This address is called the host's IP address. This address is typically broken up to a network ID - identifying the network the host is on - and a host ID - identifying the actual host on the network. IP addresses are usually broken up into four bytes and written in a notation called the Dotted Quad Notation, e.g. 146.231.128.1. The first three bytes of the above address (146.231.128) show the network address while the last one (1) shows the host number in that network. There are variations to the above, commonly referred to as subnets. The basic principle here is to separate one network into smaller ``subnetworks'' - for easier administration, for example. For a more in depth-look at subnetting, the reader is referred to [23],[29] and [31].
Routers are devices that perform the routing of IP datagrams based on their addresses. Each router has routing tables defining where traffic to a certain network should be sent. If the router does not have a direct link to the desired network, it will pass the datagram onto a router that is closer to the destination than it is. Many routing algorithms have been devised, the most popular of which is the Routing Information Protocol (RIP). RIP is a vector-distance algorithm that divides participants into active and passive machines. Passive hosts are usually normal hosts. They never broadcast information, they only listen to broadcasts and update their routing tables. The active participants are usually routers and they are allowed to broadcast routing changes. This broadcasting of information happens every 30 seconds. The information broadcast consist of an IP network and the distance (in hops) from that router to that IP network.
Instead of letting routers choose which route a packet is to take to get to a destination network, the sender may also be allowed to choose his own route for the packets. This is called source-routing. When the packet is sent out, it has addresses of the route it is to travel to get to its destination. The reverse route is taken when coming back to the source machine. There are two types of source routing, strict and loose. When using strict source routing, the exact path the packet has to travel is specified. Loose source routing on the other hand specifies addresses that the datagram must traverse, while allowing the datagram to pass through any intermediate routers.
As mentioned earlier, routing happens at the IP layer and Ethernet addresses
are 48 bits long whereas IP addresses are 32 bits long. A mapping from an IP
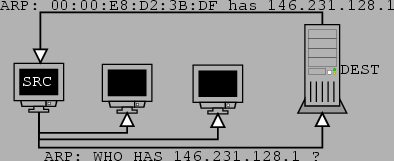
address to an Ethernet address is needed. The Address Resolution Protocol (ARP)
provides a means for the mapping. When an IP datagram is to be sent, either
the Ethernet address of the destination host or that of a gateway has to be
known. Each host has a table called the ARP cache. This table contains a list
of IP address to Ethernet address mappings. To check if the Ethernet address
of either of the above is known, the sender consults its ARP cache. If the address
is known, then the datagram is sent out. If however it is not known, the sender
broadcasts an ARP request to all hosts on the network. All the network hosts
that receive this broadcast can then update their ARP caches to include the
IP and Ethernet addresses of the sender. The desired host or its gateway will
reply to the ARP request message with an ARP reply containing the IP address
with its corresponding Ethernet address. This process is illustrated in figure
4.2.
IP addresses are represented as numbers. Computers, find it easy to remember numbers, unlike humans. Humans remember names much better than they do numbers. For example, it is easier to remember an email address that is siviwe@rucus.ru.ac.za than it is to remember siviwe@146.231.29.2. As it turns out, rucus.ru.ac.za and 146.231.29.2 are the same host. When a user wants something to do with rucus.ru.ac.za, a mapping has to be found between the name ``rucus.ru.ac.za'' and its IP address 146.231.29.2. The Domain Name Service (DNS) provides this mapping.
A namespace was defined to group together certain ``domains''. As an example, the military (US) was called ``MIL''. Servers and subdomains inside a domain would then be prepended to the name of the domain. Domain names also used a dotted notation, as with IP addresses but the number of dots is not limited to 4 but may be as high as 256 on some implementations. Let us have another look at ``rucus.ru.ac.za'' and work with it from right to left. The ``.za'' indicates a domain, a country in this case, which is South Africa. Before that we have ``.ac'' which is used for academic institutions in South Africa. Before that we have ``.ru'' which stands for Rhodes University. Before that we have ``rucus'' which is the name of a host in the ``ru.ac.za'' domain.
Because the namespace is so big, it would be irresponsible and almost impossible to keep the entire database on a single host. The DNS defines ``name servers'' which are authoritative for the names of a particular domain. For every domain, there is only one primary nameserver and any number of secondary nameservers. The primary nameserver is the most authoritative nameserver for that domain. The secondary nameservers get their information about a domain from the primary nameserver. The DNS stores such information as name-to-IP-address mappings, nameservers for subdomains, mail exchangers for hosts and domains, gateway pointers and host information.
We already mentioned above that TCP is a reliable protocol. This may be a little misleading. TCP does not make any guarantees on the delivery of data except that it will do its best to deliver it. It is therefore more correct to refer to it as a best effort, instead of reliable, protocol. To enable this, every packet that a destination hosts receives is acknowledged. If an acknowledgement is not received within a set amount of time, called a Retransmit Timeout (RTO), the packet is retransmitted. We have already mentioned that a packet going from a source to a destination does not necessarily have a set route to get there. The route is usually decided at each point along the route. It is therefore possible for one packet to get to the destination before its logical predecessor. To solve this problem, the protocol also has sequencing information which doubles up as a security mechanism. The sequencing information is controlled by a number, called the sequence number.
Every packet transmitted, is sent with its sequence number. When the destination
gets the packet, it sends an acknowledgement packet (with its own sequence number).
To open a connection, a packet (with a sequence number) with the SYN4.2 flag is sent. An acknowledgement packet is one with the ACK bit set. To make
things easier, one packet can acknowledge a packet and send it's own data in
exchange. This is the main use of the flags on the packet. Setting up a connection
involves what is referred to as a three-way handshake. An example will
illustrate both how sequence numbers work and also the three-way handshake.
Figure 4.3 shows how connection setup and how sequence numbers work. The arrow labelled 1 shows host A telling host B that it wants to establish a connection. Host B, at label 2, sends a packet back with its own sequence number and an acknowledgement number of SEQ (HOST A) + 1. Label 2, host B is saying to host A : ``I accept your request for connection establishment. Here's my sequence number. By the way, I received packet with sequence number 100 and now expect one with sequence number 101''. As can be seen, a packet is acknowledged with its sequence number + 1. The next sequence number is the previous sequence number + 1 or the acknowledgement number of the acknowledge packet. With this method, it is improbable that an old duplicate packet will confuse the system.
TCP also has checksums and flow control built into it. If the source is sending
information faster than the destination can accept it, the source is told to
slow down. An elementary form of flow control is implemented at the IP level
using ICMP. The ICMP message ``Source Quench'' is sent back to the source
when the destination cannot handle incoming traffic. TCP uses a window mechanism
to implement flow control. There is a minimum window size which is the minimum
amount of data to be transported. If the recipient can handle more, the window
size is increased. If the recipient cannot cope with the flow, an algorithm
either lowers the window size regressively or starts it from the minimum. TCP
also allows for graceful connection shutdown. A connection is not just terminated.
The side terminating the connection makes sure the other end has sent all its
data before closing the connection.
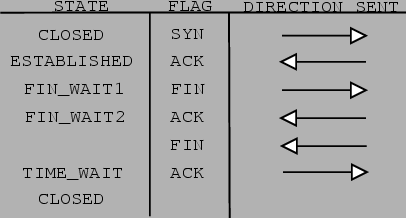
Figure 4.4 shows the different states of a TCP connection before, during and after communication. It also shows which flags are set in packets going from machine to machine. The arrows indicate the direction of traffic. The connection starts (first line) in a CLOSED state. When the ACK is received from the other host, it is ESTABLISHED. Remember that this packet has both SYN and ACK flags set. When the machine that initiated the connection acknowledges that packet, the other host will also have the connection in ESTABLISHED state. The rest of the above diagram is an illustration of how TCP gracefully closes a connection.
We have already mentioned that UDP is unreliable and connectionless. Like TCP, addressing is done with a 32-bit IP address. Unlike TCP, no promises are made on data delivery, not even that a best effort will be made to deliver it. UDP simply promises to try to deliver it, nothing more. With UDP no connections have to be setup. A packet is simply sent. If it gets lost on the network at some point, there is no retry or timeout mechanism. This protocol is very useful in high-speed communication and data transfer. The desirable features of TCP are required to be implemented by the programmer. UDP has an optional checksum. The checksum is of data, protocol header and the TCP/UDP pseudo-header. If the checksum field contains zero, the recipient of the UDP packet does not have to carry out a checksum check. In this mode, reliability of data is assumed to be taken care of by the underlying network (usually Ethernet). If the checksum is checked and found to be erroneous, it is silently discarded, unlike TCP.
So far we have discussed addressing based on the IP layer of the TCP/IP protocol stack. As many simultaneous conversation may be in progress between two hosts, UDP and TCP define port numbers. They are used to uniquely identify the session that is being held. Every packet of communication using TCP or UDP originates from some source port and is destined for a particular port number on a destination host. Communication in that session occurs through the above-mentioned ports. TCP and UDP headers therefore do not consist of IP source and destination addresses but of source and destination ports. The port number field of the TCP and UDP headers is 16 bits wide, meaning it can address 65535 ports. It should be noted at this point that TCP port 24 is not the same as UDP port 24.
Commonly used higher level protocols and applications usually have a set port number defined. As an example, the telnet application uses TCP port 23 while the DNS service uses both UDP and TCP port 53. These definitions were made on Unix machines and therefore had some security features built into them. Unix introduced the idea of privileged ports, port < 1024. To be able to bind a service on a privileged port, super-user access is required. For all other ports, no special privilege is required.
Sockets are simply a mechanism of implementing interprocess communication. They provide a high level construct to allow the making and breaking of connections. There are two ``domains'' of widely used sockets, Unix domain and Internet domain sockets. Unix domain sockets can only be used to communicate with processes on the same Unix system. Internet domain sockets are used for communication with processes that do not necessarily have to be on the same Unix system.
A socket can be created for a variety of types of communication. Types of sockets include RAW, TCP and UDP. RAW sockets are used for access to internal network interfaces and protocols. RAW types of sockets require that the creator of such a socket be the super-user, for security purposes. RAW sockets allow the user to create his own packets and work at the lowest level of the protocols. Working at the RAW level is desirable in some cases but not for wide everyday use. It is for this reason that TCP and UDP sockets are more common.
At the programming level, a socket is simply a file descriptor which can be read from and written to. This provides a layer of abstraction as the programmer never has to worry about how UDP and TCP work (for example). It is enough to simply create a socket of the Internet family, Stream type and TCP protocol to be able to make TCP connections. We have already mentioned that commonly used higher level protocols have fixed port numbers. A socket can therefore be told to ``bind'' to a specific port, instead of the operating system choosing a port for that service. Once a service has been bound to a port, no other service may bind to the port while the service is busy. At the implementation level of services such as TELNET, reading user input from a port (or writing it out to some port) simply require reading from (or writing to) some socket descriptor.
All network security problems and solutions can be looked at from two perspectives, Internal and External security. Security concerns vary depending on which perspective is the current one. Here we shall define what is meant by both perspectives of security and some of the concerns. In the theoretical and practical discussions of network security problems, very little if any distinction is made between the two perspectives. The distinction is made in the case study when intrusion attempts are viewed from both the inside and the outside.
This refers to security from the ``inside''. ``Inside'' here can mean two different things, namely inside the host, or within the network to be attacked. Our discussion in the last chapter about host security problems mainly looked at internal security from inside the host. When addressing internal security in this chapter, we shall look at security concerns from inside the network to be exploited (in other words, outside the host but inside the network to be exploited). The essence of networking is sharing of information, convenience and connectivity. It is important therefore to consider internal network security at least as seriously as internal host security. At the internal network security level, security is mostly obscured by convenience or usability.
The argument used most by those who favour little or no internal security of any kind is that they trust those on the inside. While this argument is entirely valid, it is a very short-sighted view. Consider that whoever sits inside the network sits at a privileged point and is therefore more dangerous than he who is outside. It is also important to note that in a networked environment, those on the outside can usually come inside. If an intruder were to break through the barriers on the outside and be inside the network, trust extended to legitimate users would then be extended to a complete stranger. What makes this even worse is that the stranger has shown ill-intent by breaking through the outside barriers.
In a model where it is assumed that those on the inside can be trusted, external security is probably the most important kind of security. This is the security perspective that deals with excluding those on the outside. Usability and convenience usually do not cloud security issues in this model. Security is usually first priority as no trust can be extended to the outside world to abide by the rules. The solution therefore is to keep them out and make sure they can never get in. Whoever is on the outside is not much of a threat until they come inside. By making it almost impossible to get through the barriers, a comfortable working environment can be preserved on the inside.
A backdoor does not have to provide privileged access into a system. It simply
has to provide unauthorized access into the system, which also may happen to
be privileged.
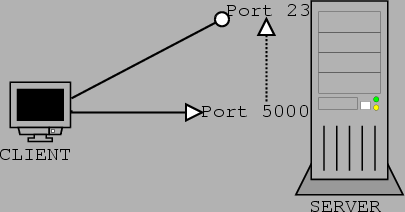
Figure 4.5 shows what is called port bouncing. The CLIENT is not allowed to connect to port 23 of the SERVER. After finding out that any host can connect to unprivileged ports, a backdoor is configured to use one of them (port 5000 in our illustration). To connect to port 23, the CLIENT connects to port 5000. The connection to port 5000 is then bounced/forwarded to port 23 of SERVER. Port 23 is the telnet port and so CLIENT will be required to authenticate himself. To make port 5000 open, we have to have access to SERVER anyway so we can assume we can authenticate ourselves. This is an example of a backdoor, since CLIENT is not authorized to connect to SERVER but does so via the ``back door''. Providing a non-passworded port with a shell is a trivial extension of opening a port for external and perhaps unauthorized entry. Several programs have been released to provide a port bouncing function, some with shells attached. The most popular of the port bouncers is called ``datapipe'' and is distributed as C source, available in Appendix A.
Most trojans are backdoors. They are the main reason that privileged access is associated with backdoors. Trojans generally provide this privileged, unauthorized access. The difference between host level trojans and network level trojans is where they are accessed from. The trojans we discussed under our host security problems are generally only accessible from inside the host. Providing a backdoor via a trojan in a networked world means that the backdoor/trojan pair has to be accessible from outside the host. Instead of providing another way to authenticate oneself for entry into the system as described above, a backdoor/trojan pair would provide privileged access without the need for [authorised] authentication. These are usually injected in a privileged state.
As discussed in section 4.1.1.1, in normal operation on ethernet, hosts look at the destination address on the packet and if it does not match their addresses, discard it without reading its contents. With packet sniffing, the network interface is instructed to open every packet that goes past it, whether destined for it or not. Armed with a packet sniffer, the attacker can read everything that goes past a particular segment of the network. The danger with packet sniffing comes in the implementation of protocols. A lot of protocols, including telnet and the r* commands, send passwords in clear-text. Anyone with a packet sniffer can therefore sniff every password and data that is broadcast on the [subnet of the] network he is on.
Port scanning in itself is relatively harmless. The use of the results of a port scan can be very harmful. It is used to determine which (mostly TCP) ports are open and listening for connections. The only ports that can be scanned with a certain degree of reliability are TCP ports since TCP is connection-oriented[19]. UDP scanning is typically done by sending a packet to a port. If an ``ICMP Unreachable'' message is received, the port is thought to not be listening. This is a very unreliable method. From this point on, port scanning will refer only to TCP port scanning. There are essentially two types of port scanning, one easily detectable and the other not.
Anyone can execute this type of scanning. It is very easy to detect on the target host because it uses TCP and establishes a connection. The theory is that if one can connect to the port, then the port is open and listening. It typically starts from a low port number, incrementing by one, and noting the ports that are open.
This type of scanning is harder to detect because a connection is not established. TCP uses a three-way handshake (SYN,ACK,DATA), with the connection being established after it is completed. There are a few implementations of stealth scanners, each of which does something different. The first method is called SYN-scanning. This method works by sending a packet, with the SYN flag set, to the host to be scanned. If the port is open on the machine being scanned, it will answer with a packet with either the SYN/ACK or RST flags set. In normal operation, the source host would finish the three-way handshake by sending an ACK. With this method it is not done, as sending the ACK would make it a normal scan. Not finishing the three-way handshake makes it harder to log as most logging happens at connection establishment. The other variation of stealth scanning is RST-scanning. This method relies on a bug in BSD networking code. There are two variations,which work by:
Off the host, Denial of Service (DoS) techniques include connection flooding and ping flooding. The most common ping flood and probably most effective is the ping of death. This technique involves sending abnormal size packets. Variants simply flood the host with so many messages that it is too busy to respond to anything else, at the same time congesting the network. Connection flooding can be broken into two categories, one easily detectable and the other not. The easily detectable one simply involves flooding a connection with a lot of requests until it finally cannot cope. The one that is not as easily detected creates a lot of ``half-open'' connections, and is called SYN flooding. It works by sending a packet to a target host with the SYN flag set, appearing to be from a host which may be down. The target host acknowledges with a packet with its SYN and ACK flags set. The target host then has a half open connection, having had two parts of the three-way handshake. The faked host never acknowledges the packet since it is unreachable. The attacker fakes more packets with their SYN flags set. Done enough times, the server sits with large numbers of half-open connections waiting for acknowledgements from an unreachable host.
Spoofing and hijacking are very similar but have some differences. In describing them, we shall group session hijacking and non-blind IP spoofing together. After that description, we shall carry on to describe blind spoofing. Thereafter we shall have a look at some of the problems associated with IP address spoofing. For the interested reader, IP Spoofing attacks are covered in a lot of detail in [3] and [14].
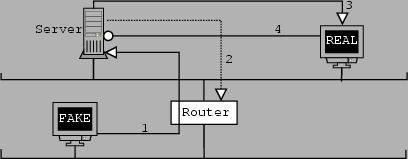
IP spoofing involves someone taking over someone else's IP address. To effectively do this, the machine, whose IP address is being taken over, is preferred to be down. The attack could be carried out when the machine is down, or more commonly, temporarily incapacitated. This method does not work well if the host being impersonated is up. Let us consider figure 4.6. The host marked FAKE is the impersonator and the host marked REAL is the host being impersonated. Host FAKE is trying to get access to SERVER. If the real host is currently logged in on the server, the fake host will not be able to login into the server. The reason for this is that replies to packets sent by the fake host will be sent to the real host. If the real host is up but not connected to the server, a session from the fake host may be accepted. If the connection from the fake host is accepted, connections from the real host will be rejected. In other words the replies to the real host's packets will be sent to the fake host.
The reason for this is that hosts and routers keep ARP (Address Resolution Protocol) tables which map IP addresses to ethernet addresses. These tables change with time. If the ARP tables on SERVER are updated every hour, FAKE or any host would have to wait an hour to be able to claim to be REAL, even when REAL is down. When a connection is active, another connection claiming to be from the same IP address is obviously fake since the server has the current connection open and can verify the IP and ethernet addresses. What also happens is that the server sends a SYN/ACK packet to the real host. The real host then responds to the server with a RST, telling it to kill the connection. Whenever the time comes for the ARP table entries to be updated, the server sends out a broadcast message enquiring as to whom a certain IP address belongs. Whichever host's reply gets to the server first will be the one that is accepted, at least until the next update period. What complicates the problem even further is the fact that ARP is a stateless protocol. This means that hosts can send ARP ``responses'' to a host that never sent a request out. When the fake responses are received, the ARP tables may be modified. This is referred to as ARP spoofing.
Session hijacking on the other hand depends on there being a current connection
between the host we plan to spoof and some server. We assume that this connection
is some trust relationship. What we try to do in session hijacking is to take
the session over from under the legitimate host's nose. Still looking at figure
4.6, the fake host is on the same network as the real host. This means that
fake host can see all the traffic or communication between the client and the
server. Our attack is based on listening in and finding out what the sequence
numbers are. Once we've got those, we reply to the server before the real host
can. To help us reply before the real host can, a denial of service attack may
be used. When the real host replies to the server, if it ever responds, its
sequence number is old and it is effectively locked out of the session. To use
the session effectively, we have to find our way back to the prompt and perhaps
put a backdoor in. This type of attack is referred to as ``Non-Blind'' since
we our traffic, the spoofed traffic and the server's response to it.
Let us consider figure 4.7 as our illustration of blind spoofing. Host FAKE wants to speak to Server but not as FAKE but as REAL. It therefore pretends to be REAL. In order to proceed effectively and be reasonably believed by Server, the REAL host has to be incapacitated. A SYN-flood could be used to keep the REAL host busy enough not to answer queries from Server. It is important to note that host FAKE is not on the same network as REAL and Server. To illustrate this on the diagram, we have put a router between the two networks. The effect this has is that even if FAKE is believed to be REAL by Server, it will never see responses from server. It therefore has to ``fly blind'' and guess what the responses of Server are. Hence the name, blind spoofing.
FAKE sends a packet with the SYN flag set to Server. Server responds with a SYN/ACK to REAL. FAKE never sees this response and has to guess. This can be done in a number of ways. One way involves making a few connections in a short amount of time to Server from FAKE, as FAKE. This will give an idea of what kind of system Server uses to generate its sequence numbers, in some cases making guessing its response easier. There are three main algorithms used for sequence number generation. They are :
As before, this attack only works when built into the relationship between REAL and Server is a big trust relationship. If there is a big trust relationship, after obtaining access, the next step is usually to install a backdoor to make intrusion easier the next time.
The Network File System (NFS) is vulnerable to IP spoofing attacks. NFS is a way for multiple systems to share a file system and work with it as if it was on the local machine. It was designed for the Arpanet environment where the one of the design features was easy sharing of information, but not security. With NFS, an NFS server ``exports'' a file system to whoever it chooses to export it to. A host in the list of hosts allowed to mount that exported file system is allowed to mount it locally based purely on its IP address. It should be a clinical matter to note that after spoofing a host whose IP address is allowed to mount the file system, the intruder is allowed to mount the filesystem. Most systems using NFS run the same operating system and share a file system to prevent duplicating the same file system n times. This kind of setup also means that changes only need to be made on one system and are visible to all systems sharing that file system. Systems set up this way extend a large amount of trust to the neighbours they export their file systems to. It should also be obvious that when an intruder has broken into one of those hosts, breaking into the others is a trivial task. An attack against NFS is described in [11].
The Network Information System (NIS) is also susceptible to IP spoofing attacks. NIS allows the sharing of a single password file by a number of systems that belong to some NIS ``domain''. There is a NIS server which keeps the passwords and maps, with the rest of the hosts in the domain being ``clients'' which use the server for authentication. NIS is often used in conjunction with NFS. NIS shares the same password among several hosts with NFS making sure that users' home directories are visible and changeable on whichever host is connected to. With this kind of setup, the hosts do not have to run the same operating system, as they share something that is not necessary for the operating system but to the users. The simplest method to fool NIS is to make the attacking host pretend to be the NIS server. The other NIS clients will do their password verification from the password maps obtained from the intruder's machine. An attack against NIS is described in more detail in [13].
The r* family of commands include rsh, rlogin and rexec. Of the three r*, remote, commands stated above rlogin and rsh are the more common. We will therefore restrict our look at r* commands to the above-mentioned two. rlogin (remote login) provides a login session on the target host, like telnet, but without the need, if setup correctly, to input a password. rsh (remote shell) works the same way. It provides a shell to execute mostly single commands on a remote host, also without the need for password input. The r* set of commands work at two levels, a host and a user level. To allow anyone from a host to remote login into the current one, that host's name is put in /etc/hosts.equiv. At a user level, a file called ``.rhosts'' in the user's home directory is needed. The contents of the file are the hostname allowed to connect, a space and the username on that machine of the person allowed to connect. For example, to allow root@gauntlet.ru.ac.za, a user would need to put ``gauntlet.ru.ac.za root'' in his .rhosts file. On a host level, faking the IP address that is allowed in /etc/hosts.equiv allows automatic entry. On a user level, both the hostname and the username pair have to be correct for the remote login attempt to be allowed.
There are three main mechanisms by which an attacker can spoof routing information; ICMP-based route spoofing, RIP-based route spoofing and source-routing based attacks. ICMP-based attacks work by sending an illegitimate ICMP redirect message to a host. The host then changes its routing table to point, not to the legitimate router, but to an attacker's machine. RIP-based attacks work by broadcasting illegitimate routing information to passive RIP hosts and routers via UDP port 520. In both of the above cases, the redirection can be made to any host chosen by the attacker. Source-routing based attacks are not very popular, the reason being that most network administrators disable source-routing. Source routing allows a user to choose a route that a packet must travel to get to its destination. Traffic coming back to that host will take the reverse route. It should be apparent that a route can be devised to go through ``laxed'' sites. In going through those ``laxed'' sites, the packet may then be able to gain entry to a secure network because of the trust extended to the ``laxed'' sites.
Spoofing of the DNS can occur when the DNS server has been compromised by a security attack. The spoof could happen in two ways; when the security attack itself modifies its tables or when the attacker modifies the tables after having compromised the security of the DNS server. DNS has two types of ``nameservers''; primary and secondary. There can only be one primary nameserver and it is the most ``authoritative'' one can find within a domain's namespace. The secondary nameservers get their infomation from the primary nameserver. If the primary nameserver has been compromised, all the secondary nameservers will have incorrect information. If such information eventually propagates throughout the entire Internet, it may have devastating effects.
ICMP packets include a payload section which is not usually used. Whether the payload is used or not, it is usually not checked. Programs like ping, which check if hosts are up or not, use ICMP. Ping works by sending ICMP echo requests and works out whether a host is up or not and other information from ICMP replies. There are no efficient filters to check what the payload section of an ICMP packet, especially since there are 15 different types of ICMP messages. Using ICMP tunnelling, covert channels can be created by putting something in the payload section of the packet. A tool exploiting this covert channel can be used as a backdoor. This backdoor can be used to execute commands on the remote system or collect information from it.