Firewalls are a means of preventing unauthorized and unwanted access to our networks. A firewall is analogous to a moat that is dug around a castle to protect those on the inside. The security intrinsic in the design of the firewall (and the moat) is that there is a single access point into and out of the network[31]. All traffic going inside and outside the network can therefore be checked and policed. These checks can be conducted in one of two ways, or both combined. The first method checks at a packet level on a host and network basis. The second method checks at the application level. The packet level check is called packet filtering while the other is called application gatewaying/proxying. Let us continue to discuss them in greater detail.
As introduced, packet filters work at a packet level. They have no concept of
users or actual information. All they know about are packet types, where they
originate and where they are destined. Blocking using packet filters is therefore
a matter of ``not allowing host X to send ICMP message'' for example. Packet
filtering is typically performed using some form of router. The router is placed
between the outside world, and the network(s) to be protected.
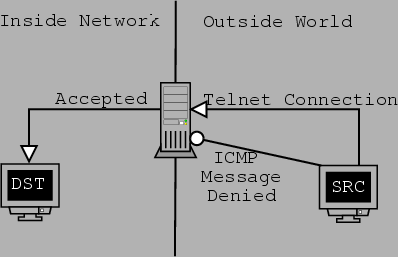
Figure 7.1 illustrates part of the working mechanism of packet filtering. A host from outside our network, SRC, uses the ``ping'' program to find out if the firewall itself or host behind it is operational. The packet filter denies the ICMP message. Telnet connections are allowed however. Host SRC tries to connect to DST inside the network. Since telnet connections from anywhere are allowed, the packet filter lets the packets through. The firewall simply acts as a police-man, examining every (incoming in our case) packet to see if it should be allowed through the ``border''.
Working at a packet level is advantageous in that it allows discrimination by source and destination addresses. Packet filters can be used to protect against most network attacks such as Blind IP spoofing and ICMP tunnelling. Not only can filtering be done on source and destination address fields but also on the source and destination ports. Different packet types can be individually discriminated. For example, telnet access could be denied to everyone outside of our network to all our servers except for a single secure host. In so doing, we not only protect networks or hosts themselves, but also provide some protection for the services that run on those servers.
As mentioned previously, the filtering router is placed between the dangerous and the protected networks. A single access router can therefore be used to protect the entire network. Another advantage of packet filtering is that it is completely user independent. Users do not have to install new custom software in order to be able to work with the firewall.
Packet filters have some disadvantages, however, three of which are listed below:
This method of filtering works at the application level. Services are restricted
based on authentication and authorization. There are two levels at which the
authentication can be done. One form of authentication is based on the source
address of connection. After the source address has been seen to be from an
authorised host, the authentication procedure begins. This stage of the procedure
is the part that requires a login name and password pair.
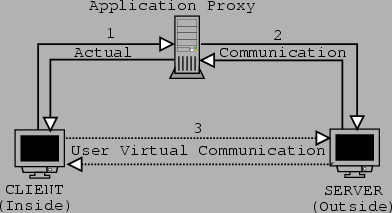
Let us consider figure 7.2 in order to describe how application proxies work. CLIENT wants to connect to SERVER's telnet port. The connection is not allowed unless it goes through the application gateway. CLIENT authenticates himself on the application proxy. When authenticated connection is made on CLIENT's behalf to SERVER, all communication from SERVER is forwarded to CLIENT and vice versa as shown by label 1. From CLIENT's perspective it appears to be speaking directly to SERVER as shown with ``Virtual Communication'' above and the label 3. SERVER does not know about CLIENT and from its perspective, it looks like it is communicating only with the application proxy. The part of the circuit that is between the application proxy and SERVER, label 2, is both a real connection and an illusion. The illusion is SERVER thinking it is communicating only with the application proxy. The way the communication works is what is represented by the solid lines and marked ``Actual Communication''.
Application proxies are also useful in control access to resources outside the network. They can be used to restrict internal network user access to the Internet for example. Users who require access for business purposes would be awarded accounts on the application proxy. Whenever they needed to access the Internet, they would have to enter their login name and password pair. Users without valid accounts on the application proxying host would be denied the service.
With application proxies, it is possible to user-level charging. All traffic inbound and outbound is logged against a particular username. This offers an advantage over packet filtering methods, which can only do host-level charging. On multi-user machines, some users may use more resources than others. To fairly charge each user for his use of the resource, an application gateway is useful.
Proxying also has some disadvantages. Here too we will discuss only three.
Access to backdoors and trojans is from outside the host to some port on the host. To prevent such backdoors and trojans, a method must be found to block ports and/or kill unknown programs bound to a local port. The blocking of ports > 1024 except for those really needed is a quick and dirty solution that will work. It however is not a perfect solution as it will also break something. When connecting to a service outside the host, a socket is created on a port (usually) > 1024 and used to connect to that host. By blocking ports > 1024, we may no longer be able to connect to other hosts' services. The backdoor is generally made use of from an outside host. We can therefore get around blocking our own outgoing packets by blocking connection originating from some other host to a port number on the local host > 1024.
Killing unknown programs bound to a local port is easily bypassed by using the execl() system call and is therefore inefficient and also ineffective. So far we have discussed solutions to access problems to backdoors but not trojans. Our solution for backdoors may not work since we mentioned that trojans are usually set up while in a privileged state. This means that the intruder can put his trojan on a port < 1024 and our filters will be ineffective in protecting us against it. The fundamental point to be noted still remains that by restricting access to the backdoor the trojan has set up, we may filter out unauthorized access. All that is needed to make our blocking solution work is to change our blocking specification to ``every service we do not require''. This would also block ports < 1024 and would therefore protect us against backdoors AND trojans.
We mentioned that packet sniffing is possible because of the normal working
operations of Ethernet. The part of the operation of Ethernet that makes it
possible and easy to carry out such an attack is the configuration of the network.
Most Ethernet networks are either in a bus or star configuration.
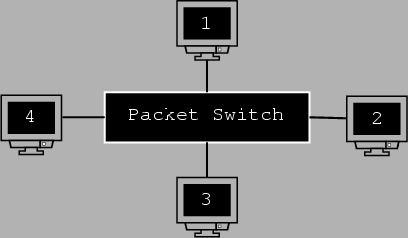
As can be seen from figure 7.3, all the hosts share the medium. In the case of the star conformation, the hub broadcasts all packets to all other hosts/ports connected to it. This is what introduces the problem. Our first solution lies in the conformation of the network and our second in the kind of data being sent down the line. The first solution is to use a switched network; the second is to encrypt data going down the ``wire''.
The switched network is just a variation of the star topology but instead of a hub in the centre, there is a switch. There is still a central ``device'' in the centre connecting all the different hosts on different ports. The difference here is that the central device has some added intelligence in that it knows the ethernet addresses of the hosts that are connected to its ports. Information destined for a particular host (say 1) from another (say 4) is not broadcast to everyone but goes from the source host and is transmitted only to the destination host. Another advantage of the switch is that it allows multiple conversations to carry on at the same time compared to the ``one at a time'' rule of the bus and hub.
This solution is the cheaper one to implement but is probably harder to implement than our first. Encryption can happen at two levels, application or link layer. Link layer encryption is the more secure of the two options but would require the abandonment of the standard TCP/IP. All information going through the medium using a link layer encryption protocol would be encrypted. Application level encryption uses applications to provide encryption. A program called ssh (Secure Shell) provides application level encryption. The application level encryption is provided by providing a tunnel through which applications can have secure communication. Applications not running through the secure tunnel do not have their data encrypted. This means for example that one could telnet (insecure and sends cleartext passwords) through an ssh tunnel and the communication be uncompromised.
A solution that has been in wide use has been to log port scans. What would then be done would be to mail the administrator of the host doing the scan asking him to investigate and generally bring it to a halt. This solution worked quite well for a while. The first reason is that the scans themselves were easy to log. The second was that the administrators on the other end were usually quite helpful. In any case, the above solution had to work as there was no other devised!
When thinking of a solution for this type of scanning, one has first to consider how to detect it. After SYN-flag scanning became popular, programs such as ``SYNlog'' were distributed to log SYN-flag scans. As far as we are aware, there is no method that has been devised to log ACK and FIN based scanning techniques. As noted in the statement of the problem of stealth scanning however, those types of scanning are based on bugs in networking software. A solution to them remains to correct the bug in the networking software of most operating systems.
From the discussions above, one of the global ``solutions'' seems to be the logging and reporting of port scans. There is however a better solution to the problem. A kernel patch (ktcpd-strobemasker-1.4) that not only logs but also does not report on the ports that are open. This means that the port scan fails because it appears that there are no open ports on the host being scanned. This is a good solution since it discourages the intruder from further port scanning.
In Linux, the ping of death vulnerability was fixed with a kernel patch. Port flooding is another problem that needed a solution. With normal port flooding, as with normal port scanning, detection is easy. As with port scanning again, the logs were mailed to the administrator of that system. The problem of SYN flooding was also ``fixed'' in this manner, using SYNlog to log the packets.
The Linux kernel was modified to include SYN and RST cookies. These are cryptographic challenges presented to the user who wants to login when a portscan is in process. Both cookies prevent the ``Denial of Service'' part of the attack. The kernel patch presented above as a global solution to port scanning also solves the problem of port flooding. In addition to not showing ports and logging the connections, it detects when the host is being flooded and ignores connections from that host for a configurable amount of time.
A solution to the problem of trust remains not to trust. In a networking environment, the solution is clearly unacceptable. A solution along the same lines but a little less brutal is to trust only those who are known to be trustworthy. Although this solution sounds reasonable, the complication is to find out who can be trusted. The solution is complicated even further by security problems. Although we know we can trust the administrator of host A, if the host has been compromised or faked, we can no longer trust anyone from that host. Since we can never know until discovery that a host that we trust has been compromised, the above solution does not hold much water either. The best solution to the problem seems to trust cautiously or reasonably. That is, to trust in a way that is not fatally wounding/damaging. In other words, trust is extended if and only if it will not be fatally damaging if the person we trust turns out to be an intruder.
In the problems section of IP spoofing we introduced the problems of stealing of IP addresses and session hijacking. We noted that stealing IP addresses is possible with ARP. We also noted that ARP itself is vulnerable to attack. One of the solutions we have to find is how to get arp to be less vulnerable to attack. This would make stealing of IP addresses a lot harder, tending towards impossible. A solution to session hijacking, although theoretically fixed by fixing ARP, still needs defining. The solution lies in encryption. There also exists a solution to both of the above-mentioned problems.
ARP provides a dynamic solution to finding out who owns a particular IP address. The solutions to ARP spoofing may include:
Encryption is a step in the right direction towards solving the problem of session hijacking. To take the session over, the intruder would have to know which encryption system is in use for that connection. For software packages such as ssh, finding the algorithm for the encryption used is not hard as it is included in the ssh package. It should be apparent that even with this basic form of encryption in place, we are still vulnerable to session hijacking attacks. A better form of implementing encryption would be a challenge based system. It would work something like the following (all data exchange is encrypted) :
HOSTA HOSTB DIRECTION ALGORITHM
1: B-Host-Key(I'm A) ----> RSA
2: A-Host-Key(Prove it) <---- RSA
3: B-Host-Key(password) ----> RSA
4: A-Host-Key(Our Key) <---- RSA
5: Our-Key(Command) ----> IDEA
6: Our-Key(Response) <---- IDEA
The solution that would complicate both ARP spoofing and session hijacking is
switching. Let us consider figure 7.4.
Consider a conversation between the hosts numbered 1 and 2 in figure 7.4. If host 3 wanted to look in on what was being said, it could not because the switch isolates the connections. For ARP spoofing, an intelligent switch is needed. When host 3 pretends to be host 2, the switch should identify that host 2 is not on that port and not allow host 3's message. This is also the case with session hijacking. When host 3 pretends to be host 2, at the right time and with the right sequence numbers to oust host 2, the switch will not let the message through to host 1 as host 2 is not on the port host 3 is on. Although the above solution solves the problem rather efficiently, hardcoding of addresses may be needed. This is undesirable for a dynamic network.
There is a simple solution to the problem of blind spoofing. Let us have another
look at the diagram representing what we try to accomplish with blind spoofing,
figure 7.5.
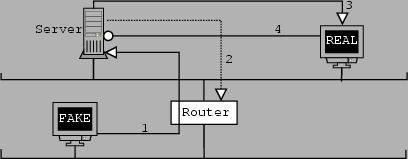
The solution to the problem is based on the fact that there is a router between the network we are on and the network we are trying to get into. The router in the above diagram seems to have two interfaces, one connecting the network to be exploited and the one we are on. Currently, the router allows us to send packets to Server pretending to be real. The solution lies in the router not allowing us to pretend to be real. Since we are on a different interface, and perhaps different subnet, to real, the router can very easily determine from which side the traffic is originating. When pretending to be real, we would then be stopped since we are not connected to the right interface or subnet.
NFS has very weak authentication. This, and the fact that it is very susceptible to misconfigurations makes it very dangerous. For some, its usefulness and ease of working is unmatched. Solutions are therefore needed for the security problems.
The first solution is to export file systems as read only. If this curbs the use of NFS, then read-write access may be preserved but only by unprivileged users. The exported file system should fall in a directory or partition where privileged accounts have no taps. By this we mean, for example, that no privileged account home directories should be in the exported file system. It may therefore also be useful to take all administrators' home directories and keep them off the exported file system, since they may have sensitive information. This solution curbs the security problems that arise from using the protocol and not its vulnerability to IP spoofing attacks.
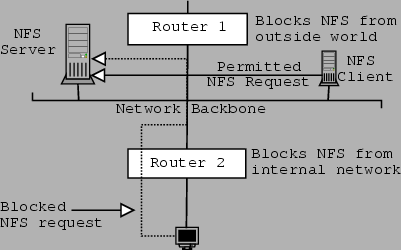
The second solution is one commonly referred to as ``throwing money at the
problem''. It involves the use of some equipment to prevent NFS requests from
dangerous parts of the network. This equipment is usually a router or a PC that
plays the role of a router. The effect is that all trusted hosts fall on the
same segment (usually the backbone) and are allowed to send NFS requests and
responses to each other. Every other host that is outside that segment or subnet
of the network is not allowed to send NFS to hosts in that segment. The scenario
described above is shown in figure 7.6.
The final solution we will discuss to the problem is to provide another form of authentication for NFS clients. If for example, a directory is exported read-only, NFS's current form of authentication is sufficient. If however, a [root] read-write directory is exported, a new way of authentication is needed. Each host that is allowed to mount this exported file system would have an entry in a password file. When the host tries to mount the file system, it also opens a random port. This random port is then connected to the NFS server's password-server-port. The client enters his password and if it is correct, the server's password daemon will send a message to its NFS server to allow the connection. For added security, the connection to the password-server-port of the NFS server would be tunnelled using ssh. This potential solution to the problem breaks the NFS protocol. This breach of protocol seems reasonable in light of the security it provides.
The solutions to ARP spoofing and the final proposed solution to NFS spoofing are applicable to NIS. As discussed in the statement of the problem with NIS, the scenarios for NFS and NIS spoofing are not the same. With NFS, depending on how the file system is exported, the client or the server can be compromised and the same effect achieved. On the other hand, NIS server spoofing is the main method of defeating NIS. By hardcoding the Ethernet address of the NIS server, clients would quickly note a faked NIS server. The intelligently switched network environment that provides a layer of protection for ARP provides a working solution for NIS too.
The final proposed solution for NFS spoofing above suggests another way in which potential NIS server spoofs may be prevented. The way the solution was proposed has been changed in order to fit in with the NIS requirements. In this solution, each client keeps a password file with the server's name and password in it. The password-server-port is thefore on the NIS clients. When the NIS clients requests the password map from the NIS server, the NIS server opens a random port and connects to the password-server-port on the NIS client. The NIS server then sends its password to the NIS client/password-server. If the password is correct, the NIS client is told to accept the password map as valid. When an intruder machine pretends to be the NIS server, we assume it will not know about the password-server and/or the password for the legitimate NIS server. As with the NFS version of this solution, the authentication connection can be (and should be) tunnelled for extra security.
A solution to the threats posed by the r* family of commands may be to use them in an ssh tunnel. Although this sounds like a very good idea, it is a redundant solution. Ssh provides for all the functions that were performed by r* commands. The best solution for prevention of spoofing attacks on r* commands is to disable them and to use ssh.
The proposed ARP spoofing solutions are also applicable to route (especially ICMP-route) spoofing. Hardcoding the ethernet addresses of routers on directly connected networks would help in preventing route spoofs. When a routing message from a fake host is received by a host, its Ethernet address will differ from that stored for the router in the permanent table. The message will then be ignored. If the legitimate router sends routing information however, the Ethernet address on the packet and that in the table will match. The host will then honour the routing information message. It should be obvious that this is a minor extension from hardcoding trusted host ARP entries. If ARP hardcoding is already in effect, the only check that will be required would be verification that the sending host is a default router. The check is implemented by default. All that is required therefore is ARP hardcoding.
The second solution proposed for ARP spoofing involved the use of an intelligent switch. The same solution could be deployed in this case. In the same way that in the case of ARP it stopped hosts faking ARP entries, it would stop hosts faking route information. Again, the same solution is applicable for both the ARP spoof and the route spoof.
The issue of DNS spoofing is mainly dependent on how secure the host and its software is. By ensuring the security of those two components, DNS spoofing becomes a smaller issue. Ensuring that there are no user accounts on the DNS server lowers the risk of host security attacks. Running the DNS software as an unprivileged user lowers the risk of software vulnerabilities. DNS is a distributed system and this is one of the complications when trying to prevent attacks. However, its distributedness also gives rise to a possible solution to DNS spoofing. The solution is based on the fact that most servers only keep one of the two maps used for resolving addresses. On most servers, the forward resolve (hostname to IP-address) maps are kept in one place and the reverse lookup tables kept elsewhere. A DNS system set up in this way needs two different DNS servers to be compromised for the attack to work properly. A solution, counting on the fact that an intruder will not compromise both DNS servers, checks each query.
If the client wishes to find the address for foo.bar.com, the fake DNS server may return the address 1.1.1.1. When the client gets this response, he asks for the reverse lookup. In other words, asks for the name associated with 1.1.1.1. The nameserver authoritative for that address (vs name) space will respond with the correct name of that host. If there is an inconsistency, the response from the first DNS is regarded as a fake. Programs using this form of checking are very effective in identifying potentially faked DNS responses to their queries. These programs include TCP wrappers, by Wietse Venema [34].
To this problem, there is no easy solution. As mentioned in our statement of the problem of ICMP tunnelling, there are currently no efficient checks for testing the payload sections of ICMP packets. A solution to this problem may be to implement such checks for the payload. This solution however would make the ICMP messaging system slow and inefficient. It is also not clear how an efficient check for the payload may be implemented. If an integrity check is implemented, the data that may be tunnelled may be modelled so that it passes the check. The problem of ICMP tunnelling has been around for a long time. It may therefore be fair and logical to assume that the use of a payload checker is an improbable solution.
The second solution to the problem is harsh but effective. Instead of trying to find out what is inside an ICMP packet, this approach denies all ICMP traffic. All ICMP packets have the payload section and so to allow any type of ICMP packet would be opening a gate for ICMP tunnelling. The global ICMP block stops the problem of ICMP tunnelling but also blocks such programs as ``ping''. Our illustration of the problem of ICMP spoofing included a firewall. A solution that may not be as brutal as closing off all ICMP traffic would be to allow it only to the firewall, and not past it. People legitimately interested in whether the network behind the firewall is functional or not would probe the firewall. If the firewall is working, it is very probable that the network behind it is also operational. If the firewall has user accounts and its security is questionable, the blanket ICMP block may be the best solution.